
Understanding the Common Service Data Model (CSDM) in ServiceNow
The Common Service Data Model (CSDM) serves as a unified framework that helps organizations manage and illustrate their services and related data…

Incident Management, overseen by those working on a Service Desk, is the practice that allows us to quickly respond to and get our customers “up and running” again when things fail. Because it’s a practice that is highly visible to our customers, it’s important that we get it right. This article will cover the Incident Management practice guide, highlighting key concepts to ensure this practice is performed successfully, as well as some of the key differences in the practice between ITIL v3 and ITIL 4.
Let’s talk about what Incident Management is and what it includes:
Purpose: To minimize the negative impact of incidents by restoring normal service operation as quickly as possible.
The Incident Management practice is about making sure that when things fail, we have a solid way of getting our customers back to “normal” quickly. It’s worth noting here that “normal” does not mean diagnosing and implementing the final, permanent solution, but rather getting our customers to a state where they can continue their work. Incident Management is about managing and treating symptoms, not necessarily understanding root cause. More on Problem Management and the differences between how we manage incidents and problems here. When it comes to managing incidents, we should work to respond to and resolve them in agreement with what our SLAs say (more on that in our article, “An Overview of the Service Level Management Practice in ITIL 4”) and ensure our customers can carry on with their work. How we manage incidents plays a large part in the overall customer or user experience and, when done well, can increase our credibility and perception to those we serve.
This brings us to the definition of what an incident is:
Incident: An unplanned interruption to a service or reduction in the quality of a service.
Unlike a change, where an interruption is planned and scheduled, incidents take us by surprise. Incidents, however, may or may not be noticeable by a customer; and if we can resolve them without our customers even knowing an incident has happened – even better. I’ll give you a quick example on the importance of communicating incidents, regardless of whether customers see them or not. One of the technicians at a customer site was walking by a server closet in the hospital. He heard a loud beeping sound and went to investigate. It turned out that a battery back-up unit (UPS) on a server was giving an alert that it was going to fail (unfortunately, it was not being managed by an event monitoring tool). The tech had every intention of calling the network team to report the alert and get it fixed. At the same time, his girlfriend called, they got into an argument, he got distracted, forgot to call the network team, and the UPS went down. Luckily, the server didn’t go down as it was supporting a live patient system. The networking team didn’t have a spare UPS in stock; and the vendor said it would take a couple of weeks to get a new one even with a rush order. They ended up borrowing a UPS unit from a less important system to support the patient system until a new unit could be put in place. Fortunately, everything ended well in this story. The point here is that “life happens,” and it’s key to communicate failures (even if it’s just a backup as it could be supporting something critical), and incidents should be sent to the Service Desk as our single point of contact – if for no other reason than to ensure that somebody is paying attention to them – and to avoid last-minute crises.
Also, the earlier that we can detect and resolve incidents, the better. Having good practices around Monitoring and Event Management (to raise alarms as soon as something fails rather than waiting until a technician walks by a server closet or a customer calls the Service Desk, implementing self-healing systems, etc.) and using automation in how we handle incidents (with automatic categorization, routing, resolution, customer notifications, machine learning solutions, etc.) can help. Having a solid knowledge-base can also help teams resolve incidents quickly (more on knowledge sharing and Knowledge-Centered Service or KCS here).
Having pre-defined ways of handling common types of incidents – or what’s called an “incident model” – can also help:
Incident model: A repeatable approach to the management of a particular type of incident.
By creating incident models, we don’t waste precious time “reinventing the wheel” with common incidents we’ve seen before and can thereby speed up how we handle them.
In catastrophic situations (fires, floods, tornados, and, unfortunately, we can add pandemics to this list) or, alternatively, in situations where there’s a lot of complexity and it’s not immediately clear what has failed, it’s helpful to have separate procedures. These situations, depending on their nature, may cause us to invoke our continuity or disaster recovery procedures; and those teams or individuals that are handling these types of incidents would often categorize them as “major incidents”, as defined here:
Major incident: An incident with significant business impact, requiring an immediate coordinated resolution.
Major incidents need to be resolved quickly as they can have far-reaching, negative consequences on our customers and the overall organization. The Incident Management practice guide has some helpful details that should be discussed and defined within an organization when it comes to “major incidents”, namely, that our models for handling major incidents should include:
There are other special types of incidents that need to be defined and managed within this practice, namely, that of security-related incidents. The Service Desk needs to be aware of when to identify and how to handle these types of incidents as they will require separate procedures and are managed by the security team or other relevant groups to ensure they are addressed quickly and effectively. InfoSec is such an integral part of everything an organization does, and it’s a substantial piece of Incident Management as well.
Swarming is a term that is new to Incident Management (introduced as part of the ITIL 4 framework), though Agile teams have been doing this for some time. It can be defined as:
Swarming: A technique for solving various complex tasks. In swarming, multiple people with different areas of expertise work together on a task until it becomes clear which competencies are the most relevant and needed.
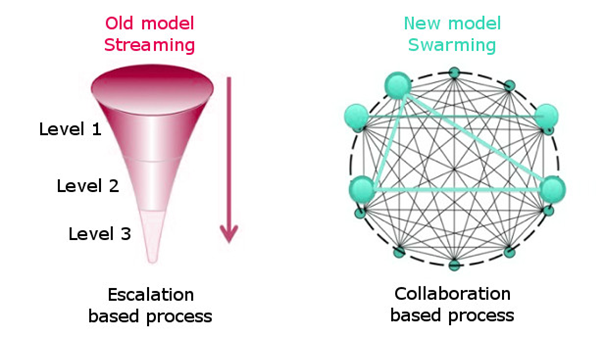
Just as a swarm of bees or ants would quickly gather together, and in concert, to contribute to the larger group so that the entire hive/colony succeeds, analysts would gather to provide their collective expertise to an incident. This approach can be especially helpful when dealing with complex incidents or those where a particular group is having a hard time resolving it – and this can include how we handle major incidents. The Consortium for Service Innovation™ has a term called Intelligent Swarming℠ that’s pretty interesting. The diagram below shows the difference between more traditional ways of escalating incidents – also called “streaming” and that of swarming.
In some cases, we may not be able to identify or implement the final solution, and that’s where workarounds can help. They are defined as follows:
Workaround: A solution that reduces or eliminates the impact of an incident or problem for which a full resolution is not yet available. Some workarounds reduce the likelihood of incidents.
One thing to keep in mind when applying workarounds is that they can increase technical debt (see the definition below) within an organization and, where possible, the cause of the incident should be identified and resolved.
Technical Debt: taking short cuts and delivering work that is not quite right for the task of the moment, a team incurs “technical debt”. This debt decreases productivity; and this loss of productivity is the interest resulting from the “technical debt”.
The purpose and definitions in the ITIL 4 Incident Management practice are pretty much the same as they were in ITIL v3. The main difference is that the practice guide expands on existing concepts in the following areas:
The Incident Management workflow that was included as part of ITIL v3 has been replaced by two sample workflows for: 1) handling incidents (detection, registration, classification, diagnosis, resolution, and closure), which can be done manually or automatically, and 2) periodic review of incidents. The practice has also been simplified to include the bare necessities when it comes to managing incidents. For example, all incidents should be:
The Incident Management practice guide mentions SLAs and how we should work to resolve incidents in alignment with what we’ve committed to with our customers.
Agile and Lean-related tools and techniques can also be helpful to teams that are managing incidents, for example, with: 1) the use of Kanban boards to make overall work and prioritization visible, and 2) limiting the amount of Work in Progress (WIP) to ensure we’re not trying to tackle too many things at once, which can decrease our overall flow and the speed at which we can get things done. Last, we should continually look for ways to get better at managing incidents – whether that be after handling “major incidents”, as new types of incidents arise, or at times when we don’t meet our SLAs.
The Incident Management practice guide also talks a bit about team dynamics to support overall success of the practice. This includes creating an environment where our teams exhibit:
All of the ITIL practices now include Practice Success Factor or PSFs (which were referred to as Critical Success Factors or CSFs in ITIL v3). The PSFs for Incident Management include:
The practice guide also provides several specific metrics we can use to make sure we’re meeting our PSFs. These PSFs are, essentially, the three most important questions to ask yourself and your teams when looking at the overall practice: 1) Do we detect incidents early on and have good tools to help us with that? 2) Do we do a good job of resolving incidents quickly, and are our customers satisfied with our quality of work? and, 3) Are we looking for ways to improve and are we getting better over time? If you’re doing these three things, you’re on the right path when it comes to Incident Management.

