
The Biggest ServiceNow Australia Release Updates, Explained
ServiceNow release notes aren’t exactly beach reading. They are useful, detailed, and important, but they are also written for people who need…

We’ve all been there. In fact, there is a good chance that our teams are experiencing this pain right now. There is more work to do than time to do it in. And there aren’t enough resources to work on it. Some work items fall into the “when I get to it” category while others simply fall off our radar . . . only to reappear twice as bad – due to neglect – at the most inconvenient time. Prudence suggests working on the most important items first. But how do we know we are working on the most impactful tasks, and is that really the full story? Fundamentally, the issue comes down to prioritization.
In this article, we discuss ways to prioritize operational and project tasks – essentially any unit of work that can be “ticketized” or decomposed into a discrete unit of work. Our focus is on prioritization across work streams when our team has different types of work in the queue (e.g., responding to incidents, performing maintenance, fulfilling service requests, completing tasks on projects, etc.); and we will learn about the various prioritization techniques and tools that support them, including Priority Matrices, Swarming, Kanban, and more. We will also answer the question, “What are the pros and cons of each prioritization type and when should we use them?” as well as “What does the ITIL framework or ‘body of knowledge’ recommend and how has ITIL advice on prioritization evolved over time?”
Once in the middle of a class, one of my students, an IT manager, walked out of the room to take a call. I could see through our glass training room wall that his gestures became very animated, and his face started to turn an unhealthy shade of red. During a break I asked him if everything was alright. He relayed to me that one of his best employees was just fired by the IT Director for failing to address a priority 2 incident in a timely fashion. As it turns out, the priority 2 incident was reported by a VIP. At the same time the incident was escalated to tier 2, the assigned technician was busy working on implementing a planned infrastructure change which would have caused disruption to an entire department if it failed. The technician was aware of the priority 2 incident, but he reasoned that, despite the VIP status of the incident reporter, implementing the request for change properly had a higher impact on the overall organization. Despite the reasonable logic, he was fired because the organization did not communicate any guidelines, preferences, or policies in prioritizing work (in fact, this specific issue represents more of a failure of leadership than an error in judgement on the part of the technician).
Effective organizations establish and communicate high-level guidelines to help employees make judgement calls when prioritization is in question. For example, an organization might recommend that when in doubt, staff should focus on critical (for example, P1 and P2), customer-facing incidents first over project and maintenance-related tasks and service requests. Note that this approach does not need to be a hard and fast rule, standard, best practice, or even a policy. There are always going to be exceptions, and people should use their best judgement. As a more general guideline, it sets forth high-level organizational priorities, but leaves final discretion to the employee closest to the task. Some IT professionals bristle at the promotion of guidelines over policies. They see this as an invitation to do whatever one wants to do. To be sure, policy has its place, and we have often helped organizations write incident management procedures and other policies. Just remember that no policy fully covers every situation; and rigid policies can often lead to indecision and delay, which are enemies of prioritization.
It may seem like a naïve question, but it is one worth asking. Many managers assume that prioritization is an efficiency issue. In other words, they believe that good prioritization is about getting more done in a shorter amount of time using the least resources. Although improved efficiency is sometimes a secondary benefit of prioritization, it is not the main goal.
Our need for prioritization can be summarized with four truths:
First of all, some definitions are in order. What do we mean by “demand?” Simply stated, demand is a consumer need (or want) for a particular product or service. A paying third-party consumer is willing to purchase products or services from an organization. From an internal consumer perspective, employees “demand” that incidents (break-fixes) be resolved, service requests be fulfilled, systems be maintained, projects get completed. To be sure, many successful organizations manage and even influence demand, which can have a positive impact on prioritization. Though we will not delve into demand shaping in this article, it is a worthy topic for future inquiry.
Capacity is our organization’s ability to meet the demand. In other words, to satisfy our consumers, we need to be able to supply demanded products and services and needs to have the resources (for our purposes, people, roles, skills, and time) to produce them. When our organization does not have sufficient capacity to meet demand, we miss opportunities, lose money, and disappoint customers.
Although there is often a seasonality or variability with demand, our resources, at least over the short term, often remain fixed. Thus, our organization’s inability (in most cases) to dynamically and rapidly expand resources threatens our ability to fulfill demand. When it comes down to it, prioritization in this context is really used to address time constraints. In other words, if we had unlimited time, there would be no need to consciously decide to tackle certain tasks before others. But, alas, we live in the real world.
The next several sections detail some of the ways we can handle prioritization, starting with the basics of urgency and impact.
For many years, ITIL v3 defined Priority as a combination of impact and urgency. Impact refers to how many users are affected or how significant something is to our organization. Urgency describes how quickly our organization is likely to suffer negative consequences if we do not address the issue or how quickly we need to accomplish the task at hand. The idea is to focus on work that is most valuable to our customer or our organization as a whole.
As a working definition, this description is so prevalent that IT Service Management tools like ServiceNow bake this into their formulas for calculating priority for “tickets” such as incidents, problems, service requests, and requests for change. (Note: Many people chafe at using the word, “ticket,” and I don’t disagree; but it is common enough that I have chosen to use it here.) Many organizations use an impact-urgency matrix – as shown in the figure below – to define somewhere between three and five levels of priority – 1 being the highest priority and requires immediate attention; 5 being, as one service desk agent jested with me, something that never gets done.
Despite copious definitions and examples at our disposal, such a prioritization scheme still introduces some level of subjectivity. Is this really a P1 or maybe it should be a P2? Even if we concede this unavoidable downside, it remains a “tried and true” way to sort out priority . . . but it works best when our team is only focused on one type of work. For example, Service Desk teams that only focus on resolving and triaging incidents generally find impact and urgency is an efficient way to look at priority and manage their work.
But is an impact-urgency matrix the best way to prioritize when our team is responsible for managing multiple work streams? For example, in situations where our Service Desk manages incidents as well as service requests (which, by the way, is a recommendation in the ITIL framework and a good thing to do), which type of work takes precedence? Most would say our incidents should receive higher priority since incidents are disruptive, often result in downtime or service degradation, cost our organization money, and drive down customer satisfaction. But, as they say, the devil is in the details. How do we compare a P3 incident where our end-user has lost the ability to use a network printer against a P1 “urgent” service request placed by the president of our company or other high-ranking official who needs a secure and disposable cell phone for international travel to a country known for spying on visitor technology?
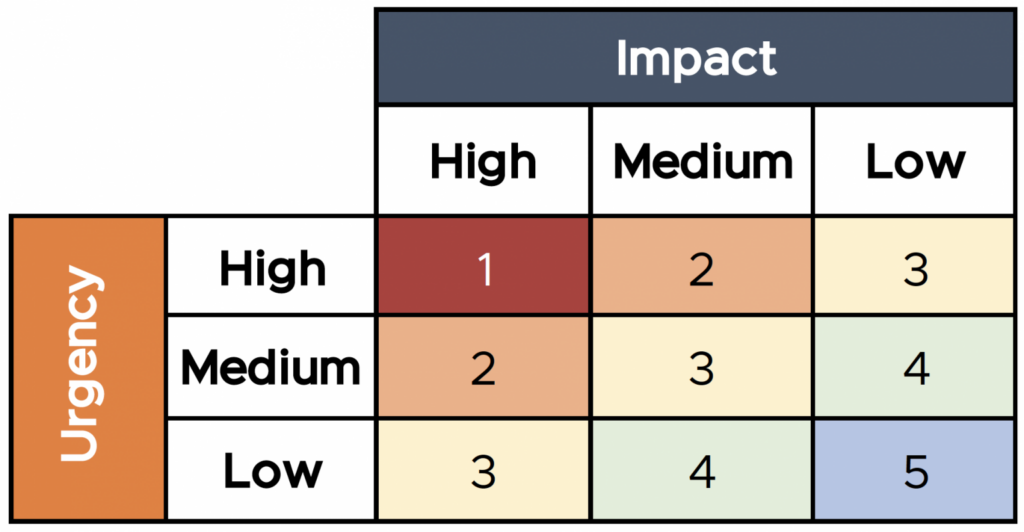
Herein lies the heart of the problem – work is relatively easy to prioritize based on impact and urgency when the work is confined to one work stream; but prioritization becomes significantly more difficult when work from more than one work or value stream has similar priority (e.g., a P3 incident versus a P1 service request). What is even more difficult is when discrete tasks performed as part of different processes and/or by different teams depend on each other to realize a value stream (more on this later).
Another way we can tackle prioritization is to look at aging techniques, which are founded on the basic recognition that the longer a task of any type sits in the queue (ie. ages), the risk that a low priority issue turns into a higher priority issue increases. These techniques aim to reduce the backlog or limit the amount of work in progress. There are two techniques: 1) Last-In, First-Out (LIFO) and 2) First-In, First-Out (FIFO) (and if you are wondering, these are also two common inventory valuation and management techniques seen in Manufacturing and Accounting disciplines).
The LIFO technique recommends that the most recent work items or “tickets” that arrive in the queue are resolved first. By addressing the most recent items first, there is a potential to keep the queue or backlog from growing and becoming unmanageable. Strictly speaking, LIFO does not take into account the complexity of the new work items, the duration to complete these items, or the associated level of effort. Thus, it may be difficult in some cases to apply LIFO with complex or time-consuming work items. In and of itself, it does nothing to address the first items in the queue, which are continuing to age. So, while it may help in preventing a burgeoning queue, it does not reduce the existing backlog.
The FIFO technique suggests, as you might imagine, the opposite of LIFO. In short, we work to first address the very first or some of the earlier items submitted in the queue. The benefit is that doing this can effectively reduce the existing backlog. It also seems “fairer” to our customers (we all believe that the person waiting in the line the longest should be served first). However, aging backlog items may be by their very nature complex or time-consuming; thus, applying this technique can actually contribute to building the new “ticket” backlog.
Neither of these techniques works well in their purest form. The best bet is to use these techniques sparingly and temporarily and usually in combination with other techniques like backlog or dispatch swarming (see below).
Duration techniques are in some ways similar to Aging techniques. The idea here is to prioritize work based on how long it takes to accomplish it. The two techniques are 1) Shortest Item First (SIF) and 2) Longest Item First (LIF).
Shortest Item First (sometimes known as WSIF for Work Shortest Item First) places a focus on reducing our backlog by working on the items we consider to be the quickest to resolve first. The benefit is that this approach can quickly reduce the backlog and limit the amount of work in progress. This technique also can help to psychologically motivate our teams because they can see how their actions are reducing the queue (nothing is more demoralizing than a long backlog). The shortest items, however, tend to be the least complex and are not always the most impactful to our business or organization. Additionally, longer duration items continue to fester in the queue.
Longest Item First (WLIF) suggests the opposite. With this approach, we tackle the longest duration items first to help remove complex issues from the backlog which may be creating bottlenecks in trying to resolve shorter duration items. Long duration work items tend to be more complex, require greater subject matter expertise, and involve greater cooperation; so, involving experts early can help prevent issues from becoming worse. However, this does nothing to de-accelerate new, lower duration items, from entering the new work queue. Thus, we might reduce the original backlog only to have a new queue build up quickly.
As with Aging techniques, Duration techniques work best when combined with backlog and dispatch swarms and temporary teams who can address long backlogs. This brings us to our next set of techniques, which come from the Agile and Lean communities.
Transparency is a powerful tool in determining prioritization. First, our teams collectively do a better job of prioritizing work than one individual such as a manager. Second, providing stakeholders with a view into the status of work items lets them know where things stand and helps improve customer satisfaction. Additionally, limiting or managing the amount of work in progress helps to remove bottlenecks and improve the flow of work. These concepts are covered from different perspectives by techniques such as Kanban Boards and Product Backlogs, which we will discuss here.
Kanban was developed as a lean management technique. The basic tenants are:
Kanban uses physical whiteboards or virtual dashboards to display to teams (and potentially customers) all work items in the backlog. Additionally, the Kanban board or dashboard (also known as one type of “information radiator”) displays work items that – at their simplest – are divided up by items that have not yet been started, items that are in-progress, or items that have been completed. Although the Kanban framework does not in and of itself suggest how to prioritize work items, the increased visibility of work allows our team to work out priority amongst themselves. It also helps our team monitor the amount of work-in-progress because generally the more we try to do simultaneously, the less likely we are to accomplish anything.
Likewise, Product Backlogs seen in agile organizations are most often used in software development and product development to list and prioritize features and enhance transparency of work items. In a product management context, a Product Manager works with our customer(s) and our product or development team to rank features in terms of priority and understand the level of effort it will take to develop each feature. Although this works best in a product management setting, it can be useful to combine other non-product or project management work items (such as defects, incidents, etc.) in one backlog. Once again, our team works with customers to prioritize the work that needs to be accomplished and can adjust priorities based on a changing situation.
Aptly, if jarringly named, swarming is what it sounds like . . . imagine a group (or “swarm,” as it were) of bees or hornets swarming around a nest. Swarming is a technique best used in cases where a complex issue arises (usually with an incident or problem) and it is difficult to identify the correct party to investigate, own, and resolve the issue. This is often the case when new complex software or systems are deployed that rely on multiple services and other applications and systems, teams, or vendors to function properly. In the early days after a deployment, it may be difficult to know which functional group or subject matter expert is in the best position to investigate and “own” an issue. For example, when I worked on implementing a new Enterprise Resource Planning (ERP) system, it was at first difficult to know the root cause of a problem or trigger for an incident – Was the application broken? Maybe the platform itself went down? Potentially the interfaces between the application and the platform are compromised? Maybe the issue is simply user error? We would open a conference bridge and assemble six to eight subject matter experts or SMEs from various functional groups to discuss the issue, run quick experiments, and ultimately determine which subject matter expert was in the best position to fully investigate and resolve the issue.
Swarming in this context can prove effective. However, proceed with caution! One organization I consulted with used swarming techniques for virtually every P1 incident. Although P1 incidents represented less than 1% of total incidents, each swarm involved between eight and fifteen tier 2 or tier 3 technicians engaged on an open conference bridge for anywhere between four and eight hours. Just imagine the salary impact of encumbering so many resources! For this particular organization, this approach consumed the equivalent, conservatively, of at least $600,000 each year. In most cases, this technique can be inefficient for simple incidents (though there is some professional debate on this point).
The goal of swarming for complex incidents should be to quickly understand where SME ownership lies and to reduce future need for swarming. As complex issues are encountered more frequently, technical ownership should become more obvious or apparent over time.
Swarming can also be used as a prioritization technique to control and reduce our backlogs, which we will discuss further in the next section.
Sometimes work really piles up. Maybe our Service Desk was short-staffed for a couple of days due to illness and low priority incidents were temporarily put on the back burner. Or our Network team was waylaid due to remediation of a failed change and several requests to provision virtual machines were put on hold. Swarming techniques can be leveraged to address situations where atypical circumstances have conspired to create unusually large backlogs. These swarms are usually manned by temporary teams and appear in three varieties:
Although no single technique can be said to be superior to another, certain techniques work better in certain situations. The table below summarizes some of the key benefits and risks of each technique we’ve discussed in this article and when they can be best employed. Note that hybrid techniques and temporary approaches to prioritization are legitimate solutions.
Organizing work into value streams can be a valuable way to obtain the outcomes we hope to achieve from prioritization. In many organizations, work is siloed, and prioritization is done on a team-by-team basis, slowing down the overall flow of work. The risk of siloed prioritization is that ultimately priority should be defined from the business and customer perspectives, not just one team. Additionally, the priority that my team assigns to a work item may not be the same that your team assigns. Organizing work into value steams that cut across our organization helps to understand and visualize work across multiple functional teams and processes. In turn, teams across the value steam can collectively determine priority of work items. Also, the more clarity a leadership team can give to their staff as to what project, programs, and other work is most important to the organization in achieving its mission or vision, the easier time that teams will have in prioritizing their own work. Prioritization isn’t just for our teams doing the work – good prioritization starts at the top.
As you have probably seen by now, there are no hard and fast rules on determining the best approach to prioritization. The context for each organization is different, and even within the same organization, dynamic situations often compel re-examination of entrenched ways of working. There are, however, some basic “dos and don’ts” to keep in mind:
Do:
Don’t:

